Applications
POETS - Partial Ordered Event Triggered Systems - technology is based on the idea of an extremely large number (millions) of small cores, embedded in a fast, bespoke, hardware, parallel communications infrastructure - the core mesh. Inter-core communication is asynchronous, and effected by small, fixed size, hardware data packets (a few bytes) - messages. For an important set of industrial problems, POETS architectures are capable of delivering orders of magnitude speed increases at significantly lower power levels.
Event-based Micromagnetic Simulation of Spintronic Devices

Moore's Law is the observation that, on a dense integrated circuit, the number of transistors doubles every two years. While this pace has slowed since the original observation in 1965, reducing the size of devices is still a strong design constraint, along with reducing the power required to operate them.
Regarding data storage in computers, hard drives magnetise regions of the space either "up" or "down" into magnetised domains. Spintronics research over the last decade has realised several alternative potential data carriers, such as skyrmions and magnons, which are both considerably smaller in size, and require less energy to drive through a material. If these properties can be exploited, the size and power requirements of devices can be reduced considerably. The micromagnetic model (a mathematical model) can be used to simulate spintronic devices. However, present computing technology imposes a practical restriction on the size of these models, restricting the scope for designing these devices.
The objective of this project is to develop an application for POETS to perform micromagnetic simulations of these potential data carriers (skyrmions and magnons), which in turn will inform the design of spintronic devices.
- For further details on this project, please contact
Dr Mark Vousden (m.vousden@soton.ac.uk)
or Prof Andrew Brown (adb@ecs.soton.ac.uk)
Department of Electronics and Computer Science
University of Southampton
Hampshire SO17 1BJ
+44 (0)2380 593374
Efficient Application Mapping for Massively Parallel Hardware
Modern processors are almost all multicore, supporting multiple simultaneous processes that can, in principle, deliver greatly improved performance with parallelisable applications. In additional to conventional mainstream CPUs, platforms such as GPUs and even FPGAs which can offer interesting mixes of greater parallelism and more application-specific processing capability are becoming very popular. On the other hand, determining how to program such systems remains nontrivial. In addition to extracting what parallelism exists in the application, there is also the often-daunting challenge of mapping parallel code to the available hardware to make best use of resources.
One class of problems that is particularly suitable for parallel processing are simulations that can be cast into the form of a graph containing a large number of small processing elements performing some simple computation, that interact with each other using small messages containing only a minimum of data. Such applications, critically, require only local memory; no shared memory is necessary, relieving what has historically been one of the very most challenging aspects of parallel programming: maintaining memory coherence.
Nonetheless, determining how to map such problems to available hardware is still a largely unexplored problem, in part because it is only recently that hardware has become available able to support the large-scale parallelism required. Good solutions to problems such as traffic congestion and local processing hotspots are still thin on the ground and often confined to very narrow application domains. There is a major research opportunity in the development of efficient, general-purpose mapping algorithms for parallel systems that can start from an abstract graph representation of the problem and produce a hardware graph representing the problem as mapped to the physical hardware.
Such tools are of immediate value in industrial applications ranging from computational chemistry to fluid dynamics. There is the potential to reduce the compute times in the large-scale simulations run in such industries from days to minutes, using much more economical hardware than the supercomputers in common use for such problems. Furthermore, by enabling such rapid, relatively lightweight simulation cycles, it becomes possible to run multiple parameter sweeps in high-dimensional spaces, in parallel simply by mapping different parameter subspaces to different processors. This capability is particularly attractive e.g. for automated drug discovery and economic modelling. This research project will develop effective mapping (hardware place-and-route) algorithms for graph-based problems. The project will work with a generic, massively parallel hardware substrate being developed by the project partners. The goal will be not merely to discover effective point solutions, but to determine what general principles for hardware mapping can be derived, so that parallel programs can be designed using a structured approach rather than through a collection of heuristics and ad-hoc techniques.
- For further details on this project, please contact
Dr Mark Vousden (m.vousden@soton.ac.uk),
Dr Graeme Bragg (gmb@ecs.soton.ac.uk),
or Prof Andrew Brown (adb@ecs.soton.ac.uk)
Department of Electronics and Computer Science
University of Southampton
Hampshire SO17 1BJ
+44 (0)2380 593374
Real-Time System Management for Asynchronous Hardware
In large computing systems, system management is a vital part of the overall platform. A system management suite must provide process monitoring, hardware diagnostics, low-level debug facilities, hardware performance monitoring, and operator control. For conventional large-scale synchronous systems, the problem has been well-studied and numerous tools offer comprehensive control and monitoring facilities. However, when the system is partially or completely asynchronous, a range of further considerations enter. For example, the concept of a global 'breakpoint' does not even apply, because various parts of the system may independently be at different points in the computation. Control messages, furthermore, must account for the fact both that the communication delay from the control source to the control target is significant, and that the exact point when the control is injected is nondeterministic. Even a seemingly trivial problem like halting an application can be complex when there may be no way of determining when a process can be safely stopped.
One possible solution is to distribute a number of independent control processes throughout the system, that assume local responsibility for a subset of the hardware and act more-or-less autonomously to provide a form of asynchronous hardware management. On the other hand, this can consume resources and occupy more communication bandwidth, so careful design will be required in order to make sure the management layer does not interfere with the main computation. Another solution would be to make each parallel process, in effect, responsible for its own management and implement a messaging system that allows a central operator control console to query each process independently. In this scenario, however, how to transform a series of local views into a global view of the overall system status will require investigation.
Such management tools may be useful not only for integrated asynchronous hardware platforms, but also for distributed systems such as sensor networks, IoT-like environments involving large numbers of embedded devices communicating using asynchronous messaging, and swarm robotics. Indeed, existing techniques used in these application domains might be adapted and used for asynchronous hardware.
This project will investigate suitable models for real-time management of an asynchronous parallel hardware platform. The project will work with a generic, massively parallel hardware substrate being developed by collaborators at the University of Cambridge and with configuration tools already under development at Southampton. The goal will be to determine what methods are suitable for managing asynchronous systems in real time and to demonstrate effective techniques through the implementation of a management layer for the hardware.
- For further details on this project, please contact
Dr Mark Vousden (m.vousden@soton.ac.uk),
Dr Graeme Bragg (gmb@ecs.soton.ac.uk),
or Prof Andrew Brown (adb@ecs.soton.ac.uk)
Department of Electronics and Computer Science
University of Southampton
Hampshire SO17 1BJ
+44 (0)2380 593374
NEUROSCAPE - a Virtual Reality Artificial Environment for simulated neural development studies

Event-based processing is a completely novel kind of computation technique, which bears little or no resemblance to Turing's original concept of sixty years ago. One of the triumphs of the technique is to be able to simulate the behaviour of massive aggregates of neurons, on a scale and at a speed unattainable with conventional machines. The headline goal is to be able to simulate the behaviour of a billion neurons in real time, using around a million conventional cores. As neural ensembles become ever more complex, amongst the technical challenges facing the human experimenter is that of interpreting the output: a billion time histories is a formidable mass of data to mine. Received neuroscience wisdom says that the best way to study the high-level behaviour of a large neural ensemble is to embed it in a virtual reality environment, where complex emergent behaviour can be (relatively) easily identified and manipulated. To achieve this requires that the simulation is capable of reacting to stimuli in real time, and this is just what event-based processing can do.
Artificial environments provide the de facto technique for neural development studies, supporting a controlled environment for real-time interaction with
- (Models of) primitive organisms hosted by the POETS engine
- (Models of) primitive organisms hosted on conventional machines
- Human operators
This project will focus in the design and interfacing of a virtual environment, to support neurobiological development studies of primitive creatures within the simulation environment.
- For further details on this project, please contact
Dr Graeme Bragg (gmb@ecs.soton.ac.uk),
or Prof Andrew Brown (adb@ecs.soton.ac.uk)
Department of Electronics and Computer Science
University of Southampton
Hampshire SO17 1BJ
+44 (0)2380 593374
Runtime Performance and Energy Optimisation of Massively Parallel Asynchronous Systems
Energy used by computing is currently estimated to account for 8% of the global electricity supply and recent predictions have suggested that datacentres will consume 20% by 2025. One way in which this problem is being addressed is through significant research into techniques for the management of contemporary multi-core and distributed HPC systems that reduce energy while maintaining application performance. Common techniques include, but are not limited to, power gating, where unused parts of a system are turned off to reduce static energy; task mapping, to efficiently use available hardware resources and facilitate other management techniques; and dynamic Voltage-frequency selection (DVFS), where the operating frequency and core voltage are varied during runtime to reduce dynamic energy.
State-of-the-art techniques can reduce the energy required to execute an application by upwards of 40% while significantly reducing idle power dissipation compared to using no management. Runtime management has also found its way into the consumer space with personal computers implementing DVFS by default and many mobile devices exploiting heterogeneous system architectures that mix energy-efficient and high-performance processing cores.
While the POETS architecture is intended to reduce power through its design, the application of management techniques that improve energy efficiency to achieve even greater savings of event-driven asynchronous many-core massively-parallel systems is a largely unexplored area that is essential to the ongoing maturation of these systems.
The objective of this project is to investigate and assess the applicability of existing state-of-the art system optimisation methods to POETS-like systems, which in turn will inform the design of novel optimisation methods.
- For further details on this project, please contact
Dr Graeme Bragg (gmb@ecs.soton.ac.uk),
or Prof Andrew Brown (adb@ecs.soton.ac.uk)
Department of Electronics and Computer Science
University of Southampton
Hampshire SO17 1BJ
+44 (0)2380 593374
Programming Models and Languages for Graph Description and Manipulation
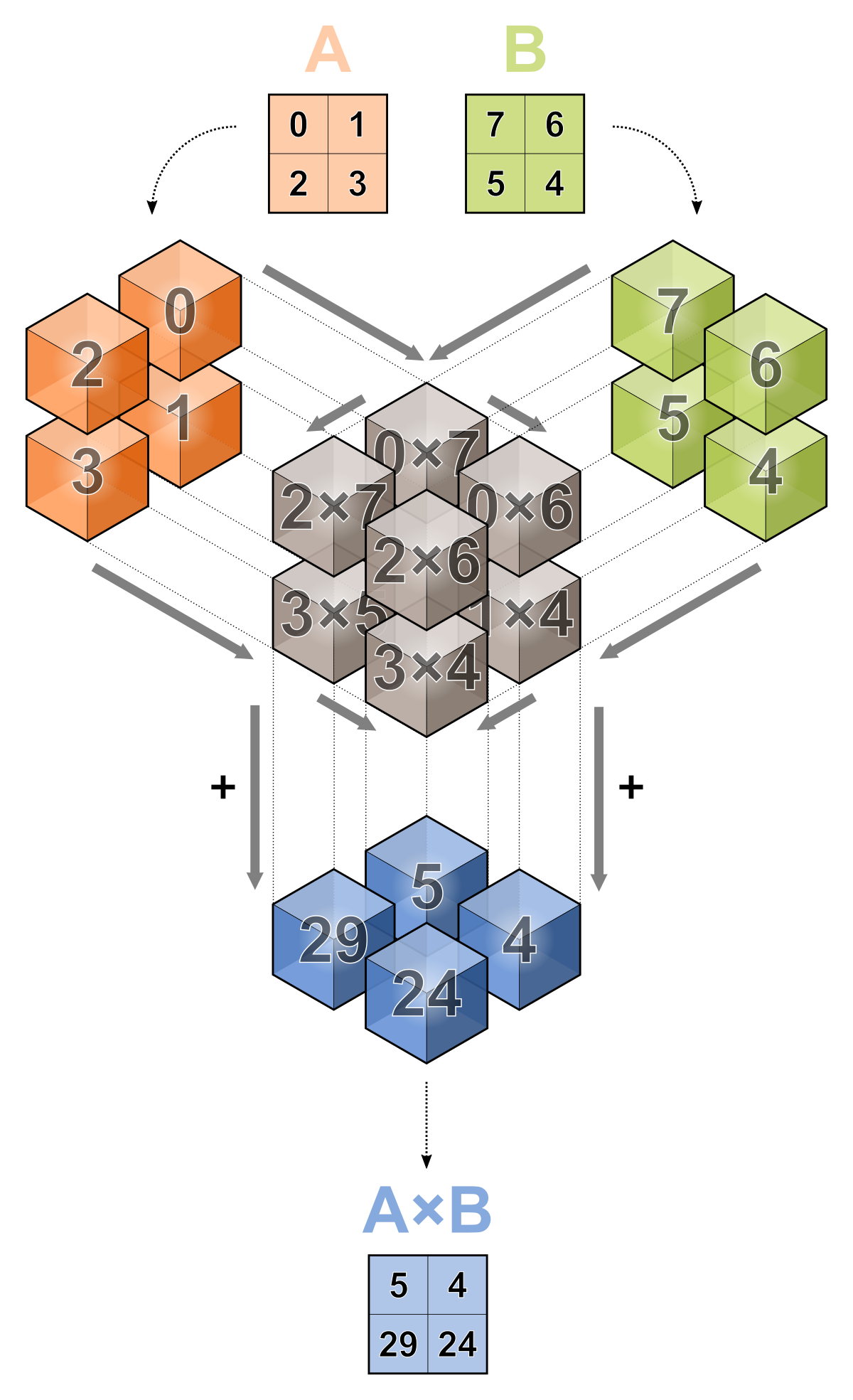
This project is about developing new programming models and languages for prototyping POETS applications that can comprise millions of nodes interacting by short messages with their neighbours. Compilation of POETS programs can therefore be formalised as construction of application graphs from high-level descriptions written in popular programming languages and frameworks, and subsequent optimisation of these graphs aiming to improve their mapping to the underlying POETS hardware, generating efficient initialisation, communication, termination and data exfiltration protocols, as well as visualising the computation process for debugging and demonstration purposes. A side illustration shows a classic distributed matrix multiplication algorithm mapped to a POETS computation network.
There is a range of possible research topics within this project that will be appealing to students with different backgrounds. Students interested in distributed systems will be able to apply their knowledge for solving real-life problems from our industrial project partners, e.g. accelerating computational drug discovery, on a newly developed distributed architecture. For mathematically inclined students, the project provides an opportunity to be involved in the ongoing work on the algebra of graphs, which is used as the underlying language for describing and manipulating graphs in our current implementation. Last but not least, students interested in formal methods will be able to contribute by formally proving key properties of the compiler backend, such as correctness and termination of generated code.
- For further details on this project, please contact
Prof Alex Yakovlev (alex.yakovlev@newcastle.ac.uk) or
Dr Ashur Rafiev (ashur.rafiev@newcastle.ac.uk)
School of Engineering,
Newcastle University
United Kingdom, NE1 7RU
+44 (0)191 208 8184
Distributed Computations on Large Scale Networks
Network science is an emerging field that combines exciting developments across broad multidisciplinary areas. Technological advances in the last decade made it possible to collect very large volumes of data and construct biological, financial and social networks of unprecedented scales, powering applications such as computational drug discovery, fraud detection and recommendation systems among others. As more data becomes available, network science is becoming increasingly dependent on our ability to run complex algorithms on large networks, a computational problem that scales poorly on commodity computers.
This research project will investigate software programming models, formalisms, tools and algorithms to tackle the scalability of network analysis on a novel distributed platform: Partially Ordered Event Triggered Systems (POETS). POETS is a new massively-parallel architecture that integrates a very large number of simple cores in a communication infrastructure optimized for delivering small messages. While many massively-parallel machines emphasize individual core performance, POETS focuses on low-latency communication and scalability; targeted computational problems are decomposed, mapped then solved by exchanging messages between neighbouring cores. This idea was first proposed to tackle large-scale physical system simulations (e.g. neural system modelling and finite element analysis) but has since proved applicable to other classes of interesting problems including network analysis.
Distributed systems such as POETS can outperform conventional shared-memory architectures in terms of scalability but require novel software abstractions that facilitate bottom-up re-thinking of problems and adapting them to a new computing medium. This is a rich and exciting research field with potentially significant impact on many real-world applications. The successful candidate will develop expertise in distributed computing as well as one or several network science application areas such as computational drug discovery and fraud detection. This studentship also provides an opportunity to interact with other research teams working on various layers of the POETS stack as well as a number of industrial partners.
- For further details on this project, please contact
Prof Alex Yakovlev (alex.yakovlev@newcastle.ac.uk) or
Dr Ashur Rafiev (ashur.rafiev@newcastle.ac.uk)
School of Engineering,
Newcastle University
United Kingdom, NE1 7RU
+44 (0)191 208 8184
Detecting Financial Fraud
The global financial system facilitates billions of transactions every day, in a spectrum of value and complexity. Some proportion of these are fraudulent, and the global financial institutions are locked in a perpetual arms-race with criminals to discover and defeat the illegal movement of financial instruments and assets.
The sheer scale of the transaction body means that anything other than automatic detection is simply unfeasible. One way of approaching this is to view every account on the planet as a node in a graph, and every transaction as a labelled edge within that graph.
A number of problems immediately begin to crystallise: (1) what - exactly - in graph-theoretic terms - is an "illegal transaction" (as opposed, say, to an ill-advised transaction)? and (2) how might we algorithmically detect this? (3) Any such detection has to happen in (near) real time on a dataset that is almost monotonically growing with time - it must be massively scalable. (4) The acquisition of the necessary base data is fraught with confidentiality issues.
One potential approach is to 'inject' into the graph a set of self-replicating crawlers (much like those employed in the World Wide Web to scan web pages) to look for anomalous patterns, both topological and temporal. Whilst there is nothing in this approach that cannot be achieved with conventional compute, the massive parallelism afforded by the POETS architecture allows crawler hits to be reported in minutes - much the same timeframe as a search engine will locate a newly published webpage.
- For further details on this project, please contact
Prof Alex Yakovlev (alex.yakovlev@newcastle.ac.uk) or
Dr Ashur Rafiev (ashur.rafiev@newcastle.ac.uk)
Newcastle University
+44 (0)191 208 8184
or
Dr David Thomas (d.thomas1@imperial.ac.uk)
Imperial College London
+44 (0)2075 946303
Computational Astrophysics

Image: www.pexels.com - copyright-free download
To (over-)condense many years of research into a single paragraph, in the Big Bang theory, a massive explosion many billions of years ago effectively threw out all the matter that comprises the Universe as we see it today. Most of the material was in the form of radiation, which was expelled from a small region with incredibly high energies, and has been condensing ever since. Gravitational attraction has slowed this process, and local perturbations give rise to non-uniform structure definition, resolving ultimately into stars, clusters and superclusters (planets are regarded as noise at this scale).
From a starting position of a galaxy as a rotating ball of gas, structure emerges: spiral, elliptical, diffuse, thin-disk galaxies all evolved from the same thermodynamic relaxation, yet have massively different properties. How? Why? This is a massive research field, and one which traditionally consumes vast amounts of compute resource. The aim of the project here is not to advance the understanding of galaxy formation per se, but to accelerate the computational modelling of the process.
The event-based approach involves "tiling space" with a mesh of volumes, each volume the responsibility of a single POETS core. Stars within a space tile are handled by the appropriate core, and stars moving from tile to tile are "handed over" - much in the same way a mobile phone network hands over responsibility for a call when a user moves between coverage cells. The numerical difficulty with this approach lies in the accurate transmission of long-range forces (gravity) across the core mesh. It is this aspect that will dominate the research activities of this project.
- For further details on this project, please contact
Dr Tom Kazmierski (tjk@ecs.soton.ac.uk)
or Prof Andrew Brown (adb@ecs.soton.ac.uk)
Department of Electronics and Computer Science
University of Southampton
Hampshire SO17 1BJ
+44 (0)2380 593374
Protein Ghost Recognition Using Deep Learning

The technology lends itself elegantly to a variety of neural network-type applications; one such area is that of ghost pattern recognition.
Cell biology - at the molecular level - underpins much research into biological processes and disease pathways. Understanding how pathogens interact with proteins embedded in a cell surface is critical to designing any kind of defence, and to do this we have to know the structure of all the proteins involved. These will typically be large, chain-like organic molecules. The traditional method of establishing the structure of any large, complex molecule is to purify a sample of it, crystallise it, and illuminate it with high-intensity beams of X-rays or neutrons. The resulting diffraction pattern provides valuable insights to the structure of the molecule under study (this was how the spiral structure of DNA was originally discovered). It has long been known that there exists a class of molecules that are permanently disordered - they simply have no crystalline form. The timeliness of this project lies in the fact that researchers are now beginning to realise that this class of disordered molecules is far larger than was previously thought, and a large number of these enigmatic structures have biological relevance. This obviously provides a driver for the elucidation of their structure, but traditionally obtained diffraction patterns are not sufficiently clear for automatic extraction of structural information
This research project will focus on the construction of a neural network - underpinned by POETS technology - that is capable of recognising physical structure from badly-defined diffraction patterns that are incapable of resolution by traditional methods.
- For further details on this project, please contact
Dr David Thomas (d.thomas1@imperial.ac.uk)
Imperial College London
+44 (0)2075 946303
or
Prof Andrew Brown (adb@ecs.soton.ac.uk)
University of Southampton
+44 (0)2380 593374
Real-time Simulation of Large Neural Aggregates

SpiNNaker (Spiking Neural Network Architecture) is a specialised computing engine, intended for real-time simulation of neural systems, and forms the basis of the project that led on to POETS. It consists of a mesh of 240x240 nodes, each containing 18 ARM9 processors: over a million cores, communicating via a bespoke network. Ultimately, the machine will support the simulation of up to a billion neurons in real time, allowing simulation experiments to be taken to hitherto unattainable scales. The architecture achieves this by ignoring three of the axioms of computer design: the communication fabric is non-deterministic; there is no global core synchronisation, and the system state - held in distributed memory - is not coherent. Time models itself: there is no notion of computed simulation time - wallclock time is simulation time. Whilst these design decisions are orthogonal to conventional wisdom, they bring the engine behaviour closer to its intended simulation target - neural systems. Whilst the SpiNNaker engine is a remarkable machine, it is based around ASIC technology, and so cannot be easily modified. It contains - quite deliberately - numerous design attributes that make it well-suited for its intended application domain - neural simulation, but which make it unsuitable for more general applications - hence POETS.
SpiNNaker contains within it a novel simulation algorithm, designed to deliver the response of large neural systems in real time. It interacts with the specialised hardware of SpiNNaker in ways that make it unsuitable for porting to conventional architectures, even if this were a desirable thing to do. However, POETS is derived from SpiNNaker - in the sense that both operate by the transmission of small packets - and the purpose of this project is to take the SpiNNaker simulation algorithm and transfer it to the POETS engine, with a view to comparing the performance of the two systems and perhaps being able to simulate even larger problems.
- For further details on this project, please contact
Dr Graeme Bragg (gmb@ecs.soton.ac.uk),
or Prof Andrew Brown (adb@ecs.soton.ac.uk)
Department of Electronics and Computer Science
University of Southampton
Hampshire SO17 1BJ
+44 (0)2380 593374
Dissipative Particle Dynamics (DPD)
J. Shillcock, Langmuir 2012, 28, 541-547
Computer simulations of biological and chemical systems are approaching a performance barrier: the computational cost of simulating a physical system scales at least as fast as the cube of its linear dimension. This barrier cannot be crossed by simulating atomic systems for longer because such systems have correlations that span many scales in space and time. New forces emerge on micron length scales that are largely independent of the constituent molecules' precise atomic structure: for example, the thermally excited undulations of membranes, or curvature-induced forces between proteins adsorbed to membranes. A mesoscale simulation technique called DPD - Dissipative Particle Dynamics - predicts how specific molecular details propagate upwards in length scale to influence the behaviour of large (~microns) volumes of matter, without considering each individual atom. This has enabled simulations of important biological phenomena such as bacterial toxin entry into cells during infectious disease.
The power of mesoscale simulations lies in their ability to accurately capture the thermal fluctuations always present in biological systems, and to reveal the emergence of long-range correlations not visible in simulations of small pieces of matter. Such systems are too slow to simulate on a single core (a CPU), and existing parallel simulations have the restriction that all cores must run in lock step, resulting in load balancing problems. The key to understanding living systems is therefore to simulate as nature does - asynchronously and in parallel - using an event-based computing engine.
By modelling the physical system under study as a network (graph) and assigning a dedicated core to each vertex in the graph, we get a computing system with remarkable properties:
- Each core only needs knowledge of the part of the network it represents.
- Each core only communicates with its immediate neighbours.
- Calculations performed at/on an individual core are small, simple, fast and easy.
These three components are scalable: if we want more accuracy, or to analyse a bigger system, we just add more cores.
Simulations of biological matter typically divide 3D space into a grid of small cubes and assign each cube to one core: each core then integrates the equations of motion for all the particles in its cube. All communication between cubes is handled by passing messages containing particle positions, velocities and forces. In a conventional supercomputer simulation this method is limited by the high delay of message passing, rather than just the compute time. The system speedup is therefore limited by the compute/messaging ratio of the processors. POETS breaks through this limitation in two ways: (1) by reducing each message to a small fixed size, with a very low message passing delay, and (2) dividing the volume of biological matter so finely such that each cube contains only a few atoms or molecules. The local computational cost per core is thus small and only one or two messages must be exchanged per core-pair to advance the simulation - all the cores operate in parallel. By exploiting high speed messaging we can reduce the compute costs, which translate into much larger systems eing simulated for longer, in a shorter time period.
- For further details on this project, please contact
Dr David Thomas (d.thomas1@imperial.ac.uk)
Imperial College London
+44 (0)2075 946303
or
Prof Andrew Brown (adb@ecs.soton.ac.uk)
University of Southampton
+44 (0)2380 593374
Asynchronous Numerical Algorithms
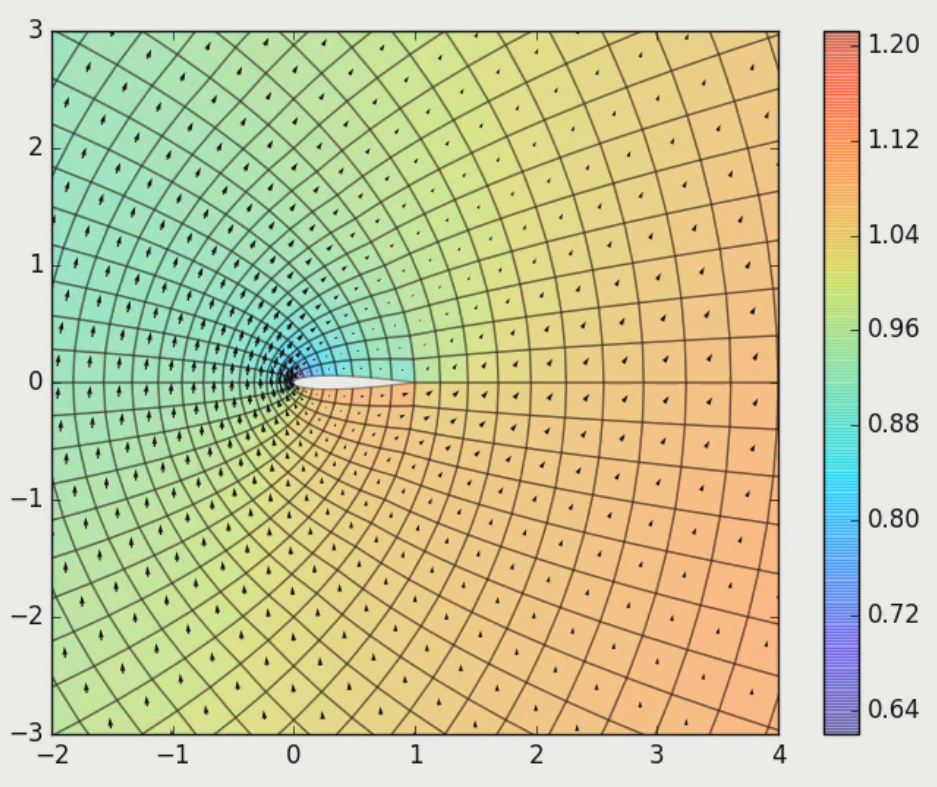
One way of using POETS is to use it to accelerate existing algorithms, but another way is to use it as a test-bed for genuinely new algorithms which directly exploit the hardware. This research project would investigate how we can transform and adapt existing synchronous numerical algorithms to work in a truly asynchronous compute fabric.
Numerical methods are widely used in science and industry to provide approximation solutions to problems which have no closed-form solutions, or are too expensive to solve exactly. Examples include n-body simulations for modelling galaxies, finite-difference solvers for modelling hydrodynamics, and finite-element simulations for evaluating wind turbines. When one thinks of the largest super-computers in the world, such as Summit, Sierra or Sunway TaihuLight, they spend most of their time executing such problems on tens or hundreds of thousands of cores. Many of these numerical methods involve stepping a simulated physical system through time, and usually will rely on the entire simulation reaching time t before any part of the simulation can move onto time t+1. This lock-step progression through time can lead to inefficiency when executing these simulations on massively parallel systems, as synchronising across thousands of cores is expensive in time and energy.
POETS offers the chance to come up with new algorithms that exploit the asynchronous nature of computers, and avoid the traditional reliance on synchronisation. The figure in the top-right shows a finite-element simulation of an airfoil, which was run on POETS using an algorithm with no synchronisation, but which still relies on discrete time steps from t to t+1. However, there is also huge scope for numerical methods which directly incorporate asynchrony at the lowest level, and can exploit the inherently un-ordered and un-predictable nature of modern large-scale distributed systems. POETS is a great test-bed for this type of research, allowing theoretical ideas to actually be tested in real-world systems. This research area would be ideal both for compute scientists and engineers interesting in algorithmic research, and also physicists or chemists who were interested in exploring the computational side of their field. This studentship also provides an opportunity to interact with other research teams working on various layers of the POETS stack as well as a number of industrial partners.
- For further details on this project, please contact
Dr David Thomas (dt10@imperial.ac.uk)
Electrical Engineering
Imperial College London
+44 (0)2075 946303